V8 딥다이브 (Map)
V8 Deep Dives: Understanding Map Internals
V8 Deep Dives: Understanding Map Internals 를 읽고 설명을 더해 정리한 글입니다.
들어가며
Map object must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The data structures used in this Map objects specification is only intended to describe the required observable semantics of Map objects. It is not intended to be a viable implementation model
— ECMAScript 2015, Section 23.1 Map Objects
Java에서는 HashMap, TreeMap 등 다양한 Map 구현체를 선택할 수 있지만, JavaScript는 new Map() 하나만 제공합니다. ES6 명세서는 Map이 해시 테이블 등으로 구현되어 준선형(sublinear) 시간 복잡도를 가져야 한다고만 명시할 뿐, 구체적인 구현 방법은 명시하지 않고 있는데요. 그래서 V8이 Map을 내부적으로 어떻게 구현했는지 알아보고자 합니다.
Deterministic Hash Table Algorithm
우선, V8의 Map은 Hash Table을 사용하여 구현되어 있습니다. 그런데 이상한 점은, Hash Table은 순서를 보장하지 않는데, ES6 명세는 Map을 순회할 때 삽입 순서를 유지하도록 요구합니다. 그래서 약간의 변형을 가한 Deterministic Hash Table Algorithm을 사용합니다.
interface Entry {
key: any
value: any
chain: number
}
interface CloseTable {
hashTable: number[]
dataTable: Entry[]
nextSlot: number
size: number
}여기서 CloseTable이 해시 테이블을 나타내는데, 이 알고리즘은 두 가지 배열을 사용합니다:
hashTable (인덱스 역할): 각 버킷이 dataTable의 어느 위치를 봐야 하는지 가리킴dataTable (저장소 역할): 삽입 순서대로 데이터를 저장하고, chain으로 연결
nextSlot은 dataTable의 다음 빈 슬롯을 가리킵니다.
// 초기 상태
hashTable: [null, null, null, null]
dataTable: []
nextSlot: 0추가
// 1단계: "apple" 추가
map.set("apple", "🍎")
hash("apple") = 2 // 2번 버킷
hashTable: [null, null, 0, null] // 2번 버킷이 dataTable의 0번 인덱스를 가리킴
dataTable: [{ key: "apple", value: "🍎", chain: -1 }] // -1 은 tail entry를 의미합니다.
nextSlot: 1apple을 추가하는 경우, dataTable[0]에 삽입 순서대로 저장됩니다. 그리고 2번 버킷은 dataTable[0]을 가리키고, tail entry를 의미하는 -1로 설정됩니다.
// 2단계: "banana" 추가
map.set("banana", "🍌")
hash("banana") = 1 // 1번 버킷
hashTable: [null, 1, 0, null] // 1번 버킷이 dataTable[1]을 가리킴
dataTable: [
{ key: "apple", value: "🍎", chain: -1 },
{ key: "banana", value: "🍌", chain: -1 },
]
nextSlot: 2banana를 추가하는 경우, dataTable[1]에 삽입 순서대로 저장됩니다. 그리고 1번 버킷은 dataTable[1]을 가리키고, 같은 버킷에 다른 엔트리가 없기 때문에 chain은 -1이 됩니다.
추가 (충돌)
// 3단계: "cherry" 추가 (충돌!)
map.set("cherry", "🍒")
hash("cherry") = 2 // 어? apple과 같은 2번 버킷!
hashTable: [null, 1, 0, null] // 2번 버킷은 여전히 0을 가리킴
dataTable: [
{ key: "apple", value: "🍎", chain: 2 },
{ key: "banana", value: "🍌", chain: -1 },
{ key: "cherry", value: "🍒", chain: -1 },
]
nextSlot: 3cherry를 추가하는 경우, dataTable[2]에 삽입 순서대로 저장됩니다. 그리고 2번 버킷은 dataTable[0]을 가리키고, apple의 chain은 2로 업데이트됩니다.
검색
// 4단계: "cherry" 검색
map.get("cherry") // 🍒를 어떻게 찾을까?
1. hash("cherry") = 2
2. hashTable[2] = 0 // 2번 버킷의 시작은 dataTable[0]
3. dataTable[0].key = "apple" // 다름!
4. dataTable[0].chain = 2 // 다음 엔트리로 이동
5. dataTable[2].key = "cherry" // 찾았다! ✅
6. return dataTable[2].valuecherry를 검색하는 경우, 해시테이블에 저장된 버킷의 시작 인덱스를 찾아서 해당 인덱스부터 순회하며 일치하는 값을 찾습니다.
삭제
// 5단계: "apple" 삭제
map.delete("apple")
hash("apple") = 2
hashTable: [null, 1, 2, null] // 2번 버킷이 이제 2를 가리킴
dataTable: [
{ key: undefined, value: undefined, chain: 2 },
{ key: "banana", value: "🍌", chain: -1 },
{ key: "cherry", value: "🍒", chain: -1 },
]
nextSlot: 3데이터를 삭제하는 경우, dataTable[0]의 key와 value를 undefined로 설정합니다. 이 때, 삭제된 자리(dataTable[0])와 nextSlot은 그대로 유지되고, 이후에 리해싱 과정을 통해 빈자리를 정리하게 됩니다.
이렇게 데이터를 저장한 뒤에는, dataTable을 순회하기만 하면 삽입 순서가 보장되게 됩니다.
시간 복잡도
set, get, delete 등 대부분의 Map 연산은 평균 O(1) 시간 복잡도를 가집니다. 최악의 경우 **O(N)**의 시간 복잡도를 가지는데, 모든 엔트리가 하나의 버킷에 몰려있고, 찾는 엔트리가 체인의 맨 끝에 있을때 N번의 이동이 필요하기 때문입니다.
리해싱 (Rehashing)
개별 연산은 저렴하지만, 리해싱은 기존 테이블의 모든 유효한 엔트리를 순회하며 새 테이블에 복사하는 작업이 필요하기 때문에 O(N) 시간 복잡도를 가집니다.
메모리 구조
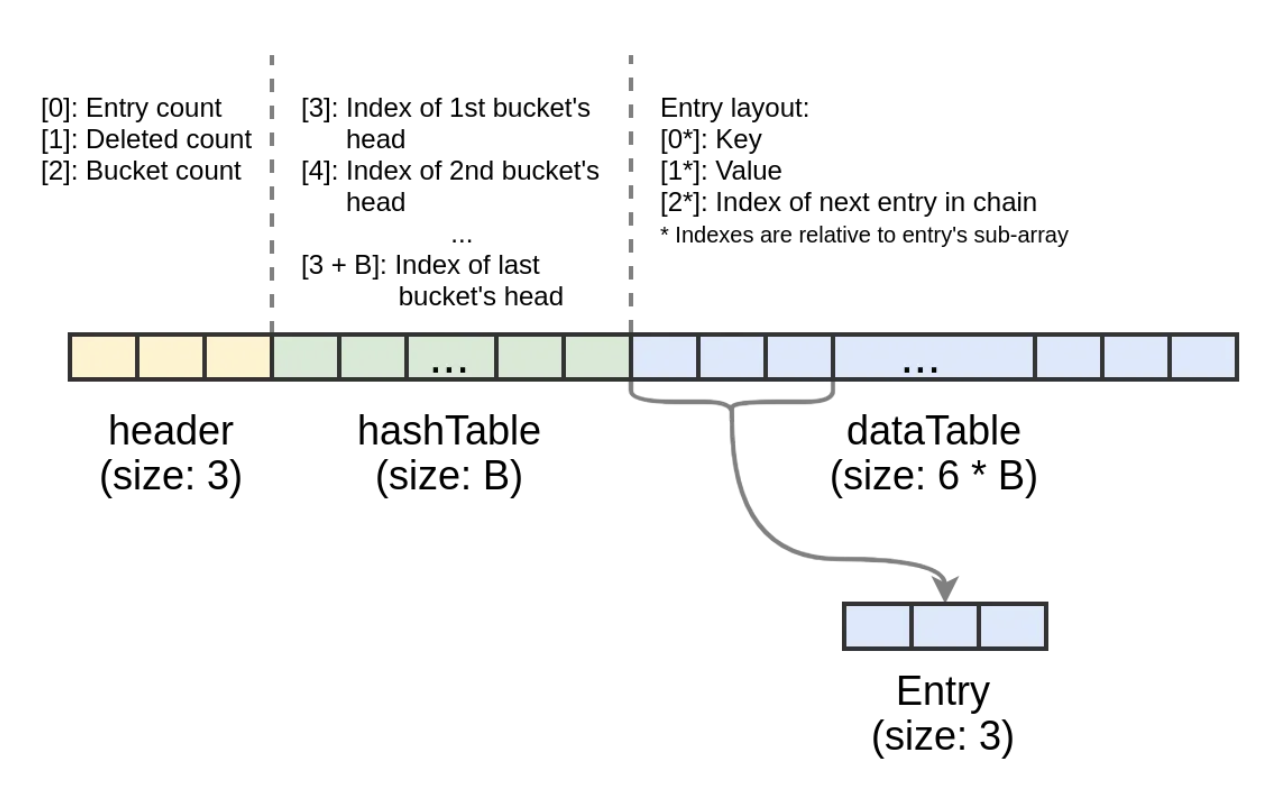
V8에서 해시 테이블은 힙(Heap) 메모리에 저장되는데, 이 저장 공간을 “backing store”라고 부릅니다. 흥미로운 점은, Map 전체가 고정 길이를 가진 하나의 배열로 저장된다는 것입니다. 배열의 구조는 아래와 같습니다:
- Header: 버킷 개수, 삭제된 엔트리 수 등 테이블 관리에 필요한 정보를 저장
- Buckets: 각 버킷이 가리키는 dataTable의 시작 인덱스를 저장
- Entries: 실제 데이터가 저장되는 영역. 각 엔트리는 배열에서 3개의 요소를 차지 (key, value, chain)
메모리 사용량
배열 크기는 대략 N × 3.5 (N = 테이블 용량)로 추정할 수 있고, 각 배열 요소는 8바이트를 차지합니다. 따라서 용량이 2²⁰ (~100만)인 Map은 약 29MB의 힙 메모리를 사용합니다.
용량 100만개인 Map의 메모리 사용량:
= 1,000,000 × 3.5 × 8 bytes
≈ 29 MB100만 개의 엔트리를 저장하는 Map이 약 29MB의 힙 메모리를 사용한다는 것을 알 수 있습니다.
Object vs Map: 언제 무엇을 사용할까?
| Map | Object |
|---|---|
| 문자열이 아닌 키 (객체, 숫자 등) | JSON 직렬화 필요할 때 |
| 빈번한 추가/삭제 | 구조 분해 할당 필요할 때 |
자주 크기 확인 (map.size) | 프로토타입 체인 필요할 때 |
| 삽입 순서 중요 | - |